La nascita della Teoria dell’informazione può essere fatta risalire al \(1948\), l’anno della pubblicazione dell’articolo ‘A mathematical theory of communication‘ di Claude Shannon (1916-2001 ). L’opera di Shannon è stata fondamentale per lo sviluppo della tecnologia digitale di trasmissione dei dati sulle reti di computer e sulla rete globale Internet. Shannon descrisse il problema della trasmissione delle informazioni con le seguenti parole:
“The fundamental problem of communication is that of reproducing at one point, either exactly or approximately, a message selected at another point.”
Prima dell’avvento della tecnologia digitale l’informazione veniva trasmessa utilizzando segnali analogici. I segnali analogici sono funzioni continue del tempo che variano in analogia con qualche grandezza fisica, come il suono, il potenziale elettrico, la pressione, ecc. La trasmissione può avvenire attraverso dei cavi o attraverso lo spazio vuoto tramite le onde elettromagnetiche. Questo tipo di tecnologia funziona bene sulle piccole distanze; tuttavia ha dei limiti sulle grandi distanze, a causa del rumore inevitabile che degrada il segnale. Il rumore pone dei limiti fondamentali alla possibilità per il destinatario di ricostruire correttamente l’informazione trasmessa.
La teoria dell’informazione sviluppata da Shannon ha dato un contributo fondamentale per superare i limiti della trasmissione analogica. Shannon propose di codificare il messaggio da trasmettere, trasformando il segnale in una struttura discreta costituita da una stringa di cifre binarie, chiamate bit. Il bit è l’unità minima di informazione che può essere usata per codificare un messaggio. Un bit può assumere solo due valori, che in genere vengono rappresentati con i simboli \(0,1\). Lungo il canale di trasmissione viene trasmesso il segnale codificato. Nel punto di arrivo si deve effettuare il procedimento opposto di decodifica, in modo da consegnare al destinatario il messaggio nella sua forma iniziale.
La trasmissione digitale ha un grande vantaggio: anche in presenza di rumore nel canale di trasmissione il segnale digitale può essere ricostruito nella sua forma iniziale. Questo permette di trasmettere informazioni in modo affidabile anche a grandissime distanze.
1) I sistemi di comunicazione – Il paradigma di Shannon
In generale lo scopo di un sistema di comunicazione è di trasmettere dei messaggi da una sorgente ad una destinazione, attraverso un canale fisico. I messaggi possono essere di vario tipo: testi, immagini, video, audio, ecc. Il canale è il mezzo in cui si propaga il segnale. Per i segnali elettrici può essere il cavo coassiale, il doppino telefonico, la fibra ottica, ecc; per i segnali sonori l’aria, mentre può essere lo spazio vuoto per i segnali inviati con onde elettromagnetiche.
La distanza fra la sorgente e il destinatario può essere molto grande, come nelle trasmissioni con i satelliti e le navicelle spaziali, oppure può essere molto piccola, come nella trasmissione dei dati fra la memoria centrale di un computer e una memoria esterna. In ogni caso fra la sorgente e il destinatario c’è sempre un canale fisico nel quale sono in genere presenti interferenze elettriche e rumori di fondo di vario tipo, che possono modificare il segnale trasmesso in modo irreparabile.
Il modello di Shannon (chiamato anche modello di Shannon-Weaver) fornisce uno schema per analizzare la trasmissione e ricezione dei messaggi. Secondo questo modello un sistema di comunicazione digitale è costituito dai seguenti componenti:
- una sorgente di informazioni;
- un dispositivo per codificare l’informazione in un formato compatibile con il canale di trasmissione;
- un canale sul quale il segnale codificato viene trasmesso;
- una sorgente di errore che è collegata al canale;
- un dispositivo di decodifica, ed eventualmente di correzione di errori inseriti durante la trasmissione;
- un destinatario dell’informazione.
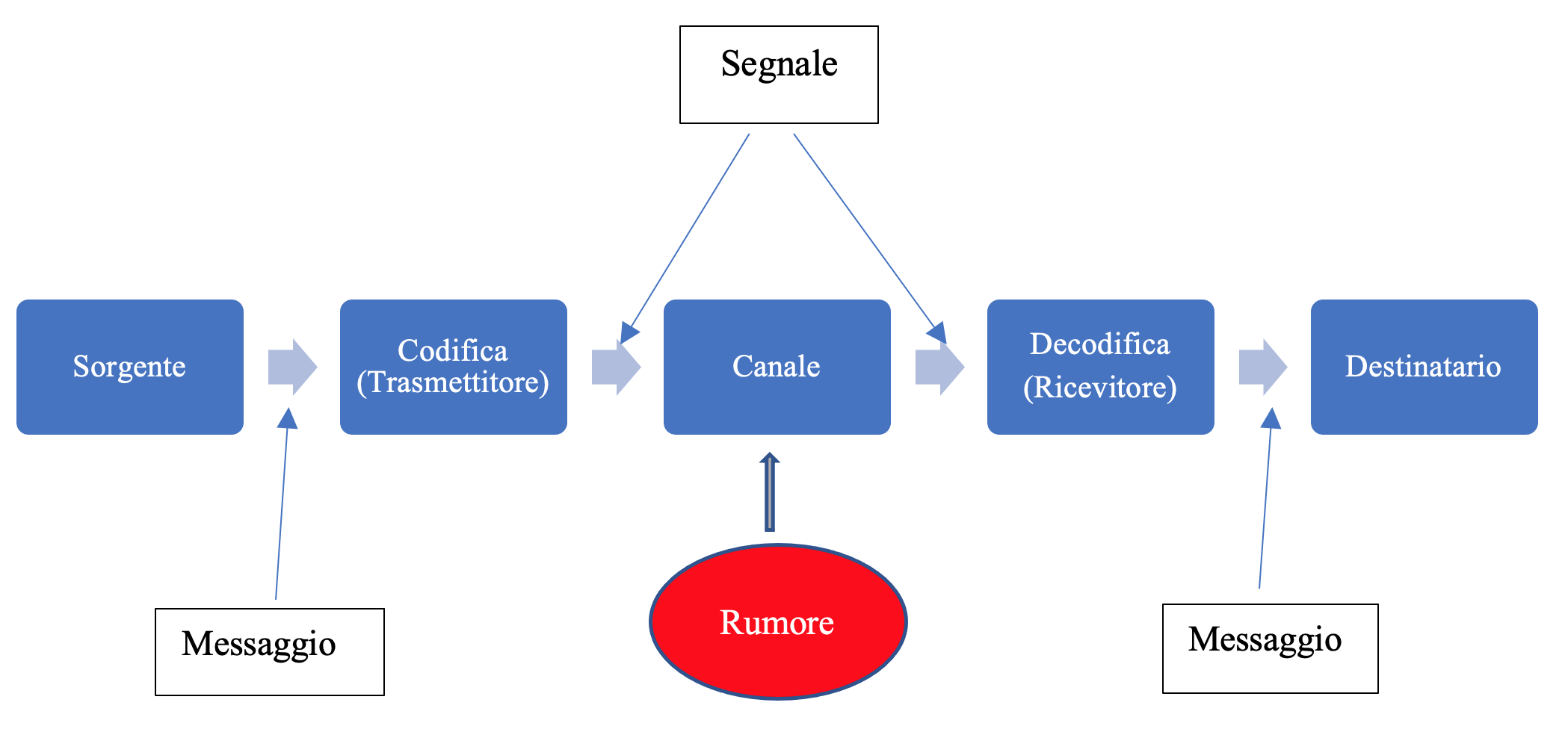
Per poter ricostruire il messaggio anche in presenza di errori di trasmissione bisogna aggiungere dei caratteri aggiuntivi di controllo al segnale che viaggia nel canale. Questa ridondanza dei caratteri inviati sul canale permette in genere di ricostruire il messaggio originale, tramite i cosiddetti codici a correzione di errore.
1.1) La sorgente delle informazioni
Il primo componente del sistema di comunicazione è la sorgente dell’informazione. La sorgente può essere ad esempio un essere umano oppure un dispositivo elettronico. In genere la sorgente e la destinazione sono separati da una distanza fisica, piccola o grande, e il messaggio viene trasmesso attraverso un canale che collega il punto di partenza con il punto di arrivo. Tuttavia nello schema di Shannon può rientrare anche il caso in cui non c’è una distanza spaziale fra la sorgente e il destinatario, ma soltanto una distanza temporale. Un messaggio viene registrato dalla sorgente in un dato istante di tempo e successivamente viene letto dal destinatario.
L’informazione generata dalla sorgente può essere di vario tipo:
- testi in un dato linguaggio
- suoni naturali o artificiali
- immagini grafiche
- immagini televisive
Ad esempio una persona che parla al telefono è una sorgente che genera informazione nella forma di suoni.
Una sorgente si dice discreta se emette una sequenza di caratteri, mentre si dice analogica o continua se emette delle grandezze fisiche continue, come l’ampiezza di un’onda, un potenziale elettrico continuo, ecc. Dal punto di vista matematico il messaggio può essere quindi una stringa di caratteri di un dato alfabeto, un funzione del tempo nel caso del messaggio telefonico, una funzione di due coordinate spaziali e una temporale nel caso delle immagini televisive in bianco e nero, ecc.
In questo articolo studieremo soltanto le sorgenti discrete. Una sorgente continua comunque può essere convertita in una sorgente discreta tramite il Teorema del campionamento di Shannon-Nyquist: per trasmettere un segnale analogico mediante una trasmissione digitale bisogna effettuare le seguenti operazioni:
- campionamento del segnale analogico
- trasformazione del campione in valori digitali
Il campionamento consiste nel registrare il valore dl segnale analogico con una certa frequenza temporale. Il teorema del campionamento afferma che se il campionamento avviene in modo uniforme ad una frequenza maggiore di almeno il doppio della massima frequenza del segnale originale, allora è possibile ricostruire perfettamente il segnale originale.
Per approfondire il teorema del campionamento veder libro di Cover [2].
Una sorgente di informazione discreta genera una sequenza finita di simboli. Definiamo l’alfabeto di una sorgente discreta l’insieme finito di simboli che la sorgente è in grado di generare:
\[ S= \{s_{1},s_{2},\cdots,s_{q}\} \]I simboli possono essere lettere dell’alfabeto, bit, sequenze di DNA, ecc.
Un messaggio di lunghezza \(m\) è una stringa \(s\) di \(m\) simboli
dove ognuno degli \(X_{k}\) è un elemento dell’insieme \(S\).
Possiamo dare una definizione formale di sorgente come processo stocastico. Ricordiamo che un processo stocastico è una collezione di variabili aleatorie \(\{X_{t}, t \in T\}\), dove \(t\) è un indice temporale che può assumere un numero finito o numerabile di valori, oppure una quantità non numerabile. Nel primo caso il processo stocastico si dice discreto, nel secondo caso si dice continuo.
Definizione 1.1
Una sorgente \(S=\{s_{1},s_{2},\cdots,s_{q}\}\) è un processo stocastico discreto \(\{X_{n}\}\), dove \(n\) è l’indice temporale e ognuna delle variabili aleatorie \(X_{n}\) può assumere i valori dell’alfabeto \(S\) con una data distribuzione di probabilità:
La sorgente può essere:
- stazionaria, se le probabilità associate ai simboli dell’alfabeto non variano nel tempo;
- senza memoria, se le variabili aleatorie \(X_{n},X_{m}\) sono indipendenti, per ogni coppia di indici \(n,m\);
- discreta, se l’alfabeto è costituito da un insieme finito o numerabile di simboli;
- binaria, se l’alfabeto è costituito da soli due simboli.
1.2) La codifica delle informazioni
In questa fase il messaggio della sorgente viene codificato e convertito in un segnale fisico, che può essere trasmesso nel canale. Il codificatore può essere un computer che codifica il messaggio in cifre binarie, oppure può essere una persona che traduce un pensiero in parole o testi scritti.
Nel prossimo paragrafo descriveremo in dettaglio il processo di codifica.
Esempio 1.1 – Il codice ASCII
Nel codice ASCII le parole codice hanno lunghezza fissa di \(8\) bit (\(1\) byte). Molti computer utilizzano questo codice per rappresentare tutte le lettere (maiuscole e minuscole) dell’alfabeto inglese, i numeri da \(0\) a \(9\), alcuni simboli speciali ed alcuni simboli di controllo. Con \(8\) bit si possono rappresentare in totale \(256\) simboli diversi.
Le parole codice hanno lunghezza fissa di \(8\) bit, indipendentemente dalla frequenza dei simboli. Ad esempio la parola “e” è la più frequente nei testi in lingua inglese, ma il suo codice ha la stessa lunghezza delle parole meno frequenti, come la lettera “z”.
1.3) Il canale di trasmissione
Il canale è il mezzo che permette al messaggio codificato di arrivare al decodificatore e quindi al destinatario. Ad esempio nel caso di invio di un una email il canale di trasmissione è la rete internet e il web.
1.4) Il rumore
Il rumore è qualunque cosa che è in grado di modificare il messaggio. Possiamo distinguere due tipi di rumore:
- rumore interno, dovuto ad errori inseriti in fase di codifica o decodifica del messaggio originale;
- rumore esterno, dovuto ad interferenze che compromettono l’integrità del messaggio originale.
Obiettivo di un sistema di comunicazione è la progettazione di algoritmi in grado di intercettare eventuali errori, e se possibile ricostruire il messaggio originale, sfruttando la ridondanza dei caratteri trasmessi.
1.5) La decodifica delle informazioni
In questa fase viene effettuata l’operazione inversa della codifica. Il messaggio codificato che è stato trasmesso attraverso il canale viene ricostruito nella sua forma originale, come era stato inviato dalla sorgente. In questo modo può essere ricevuto e compreso dal destinatario.
Esempi di decodificatori possono essere gli apparecchi telefonici che trasformano il segnale digitale in suoni, oppure i computer che trasformano la sequenza di bit in pixel per ricostruire un’immagine su uno schermo.
1.6) Destinatario del messaggio
Il destinatario è il componente finale del modello di Shannon-Weaver. È la persona o il dispositivo a cui viene consegnato il messaggio inizialmente inviato dalla sorgente.
Ad esempio il destinatario può essere una persona che legge una email inviata tramite la rete internet, oppure una navicella spaziale che riceve un comando di correzione dell’orbita da una stazione terrestre.
2) La teoria dei codici
Supponiamo di avere una sorgente che trasmette dei messaggi utilizzando simboli appartenenti ad un insieme discreto finito di simboli \(S=\{s_{1},s_{2}, \cdots ,s_{q}\}\). Ad esempio un messaggio \(s\) potrebbe essere del tipo seguente:
\[ s = X_{1}X_{2} \cdots X_{n} \]dove ognuno degli \(X_{k}\) è un elemento dell’insieme \(S\). Ogni messaggio ha una lunghezza finita, anche se non si può imporre un limite superiore finito.
Indichiamo con \(S^{*}\) l’insieme di tutti i messaggi possibili:
dove \(S^{k}\) contiene le stringhe di lunghezza \(k\). In particolare \(S^{0}\), la stringa senza simboli, viene inclusa perché è utile in alcune dimostrazioni.
Esempio 2.1
Supponiamo che la sorgente trasmetta i risultati dei lanci di una coppia di dadi. Per ogni lancio sono possibili \(36\) risultati diversi: \(S=\{(1,1),(1,2),(1,3),\cdots,(6,6)\}\). Se i dadi non sono truccati e i lanci sono indipendenti, per ogni coppia la probabilità che il primo risultato sia \(i\) e il secondo sia \(j\) è \(p(i,j)=\dfrac{1}{36}\).
Esempio 2.2
Supponiamo che la sorgente \(S\) sia costituita dai simboli utilizzati in un libro: lettere, cifre, spazi, caratteri speciali. Il testo del libro può essere considerato come una lunga stringa lineare di caratteri. La variabile \(X_{n}\) indica il carattere del libro che si trova nella posizione \(n\). In questo caso l’ipotesi della mancanza di memoria non è corretta, in quanto in genere c’è un legame tra un carattere e il precedente. Ad esempio nella lingua italiana dopo la lettera \(q\) viene sempre la lettera \(u\), tranne nella parola “soqquadro”.
La codifica di una sorgente consiste sostanzialmente nel sostituire un messaggio con un altro. I motivi principali per la codifica dei messaggi sono i seguenti:
- Ottimizzazione: i messaggi più brevi hanno vantaggi economici e anche minore probabilità di errori.
- Affidabilità: il processo di trasmissione può introdurre degli errori. Alcuni codici sono in grado di riconoscere gli errori e eventualmente di correggerli.
- Sicurezza: i messaggi che hanno un alto grado di riservatezza non devono essere intercettati da persone diverse dal destinatario.
Questi tre fattori sono alla base di tre importanti discipline della Teoria dell’informazione:
- Algoritmi per la compressione dei dati
- Codici per la rilevazione e correzione degli errori
- Crittografia e Crittoanalisi
In questo articolo studieremo il problema della codifica nel caso di canali ideali, senza la presenza del rumore che può introdurre errori nella trasmissione (noiseless channel). Nel caso di canali con rumore si devono utilizzare i cosiddetti codici a correzione di errore, che vedremo in un articolo successivo.
Per codificare i messaggi di una sorgente si usa in genere un diverso insieme di simboli.
Definizione 2.1
Sia \(S\) un insieme di simboli \(S=\{s_{1},s_{2}, \cdots ,s_{q}\}\). Sia \(D=\{d_{1},d_{2}, \cdots ,d_{r}\}\) un altro alfabeto di \(r\) elementi. Un codice è una funzione iniettiva \(C\)
dove \(D^{*}\) è l’insieme di tutte le stringhe di lunghezza finita di simboli dell’alfabeto \(D\). Per ogni simbolo \(s_{k} \in S\), la stringa \(C(s_{k})\) viene chiamata la parola codice di \(s_{k}\) (codeword). Il codice è costituito dall’insieme di tutte le parole codice.
Il codice è binario se \(r=2\). In generale se \(|D|=r\) il codice viene chiamato r-ario.
Ricordiamo che la condizione di funzione iniettiva equivale alla seguente proprietà:
Esempio 2.3
Il codice ASCII è un codice a lunghezza fissa che utilizza un alfabeto binario \(D=\{0,1\}\). Per rappresentare \(256\) caratteri diversi sono necessari \(8\) bit (1 byte) per ogni carattere.
Se i numeri compresi nell’intervallo \([0,255]\) vengono rappresentati con il sistema esadecimale, con base \(D=\{0,1, \cdots, 9, A,B,C,D,E,F\}\), allora sono sufficienti due caratteri per rappresentare i \(256\) simboli della sorgente.
Definizione 2.2 – Estensione di un codice
Dato un codice \(C\), la sua estensione \(C^{*}\) è una funzione che ad ogni stringa di lunghezza finita di simboli della sorgente assegna una stringa di lunghezza finita di parole codice. In simboli, data una stringa \(x_{1}x_{2}\cdots x_{n}\) di simboli di \(C^{*}\), abbiamo
Questa operazione si chiama anche concatenazione. Possiamo considerare la stringa \(x_{1} \cdots x_{n} \in S^{*}\) come un blocco di \(n\) simboli consecutivi trasmessi dalla sorgente \(S\), oppure una stringa lineare di \(n\) simboli indipendenti trasmessi dalla sorgente.
2.1) Codici univocamente decodificabili
In parole semplici un codice è univocamente decodificabile se è possibile decodificare ogni carattere del testo trasmesso dalla sorgente in modo univoco, senza ambiguità.
Definizione 2.3
Un codice \(C: S \to D^{*}\) si dice univocamente decodificabile se la funzione estesa
è una funzione iniettiva.
Ciò significa che ogni stringa \(w \in D^{*}\) corrisponde al massimo ad un messaggio dell’insieme \(S^{*}\), e quindi è decodificatile in modo univoco.
Esempio 2.4
Il seguente codice non è univocamente decodificatile.
Teorema 2.1
Se le parole di un codice \(C\) hanno tutte la stessa lunghezza, allora \(C\) è univocamente decodificabile.
Dimostrazione
Indichiamo con \(\lambda\) la lunghezza delle parole codice. Supponiamo che la stringa \(w \in D^{*}\) possa essere decomposta in due gruppi distinti
dove \(x_{k},y_{k} \in D\). Per l’ipotesi di lunghezza fissa abbiamo \(\lambda m= \lambda n\) e quindi \(m=n\). Ovviamente deve essere \(x_{1}=y_{1}\) in quanto sono i primi \(\lambda\) simboli della stringa \(w\). Lo stesso vale per i successivi \(x_{i},y_{i}\).
2.2) Codici a prefisso o istantanei
Definizione 2.4
Un codice \(C:S \to D^{*}\) si dice a prefisso o istantaneo (prefix-free code) se non esiste una coppia di parole codice \(w_{1}=C(s_{1})\) e \(w_{2}=C({s_{2}})\) tale che
dove \(w\) è una qualsiasi parola non vuota di \(D^{*}\).
In altre parole un codice è istantaneo se nessuna parola codice è il prefisso di un’altra. Chiaramente un codice istantaneo può essere decodificato iniziando dall’origine, senza la necessità di esaminare le parti successive del messaggio.
Esempio 2.5
Il codice seguente è istantaneo:
Il seguente teorema è facilmente dimostrabile:
Teorema 2.2
Se un codice è a prefisso allora è univocamente decodificabile.
La condizione che il codice sia a prefisso è sufficiente per essere univocamente decodificabile, ma naturalmente non è necessaria.
L’insieme delle parole codice di \(D^{*}\) può essere rappresentato mediante un grafo, in particolare un albero. Illustriamo per semplicità il caso di codice binario \(D=\{0,1\}\). Nel vertice si mette la parola vuota, che possiamo indicare con il simbolo \(\emptyset\). Dal vertice partono due archi agli estremi dei quali si pongono i simboli \(0,1\). L’operazione si ripete da ognuno degli estremi. I figli di un nodo con etichetta \(w\) vengono etichettati con \(w0\) e \(w1\). Potenzialmente si tratta di un albero di profondità infinita, potendo rappresentare stringhe del codice \(D^{*}\) di lunghezza finita qualunque.
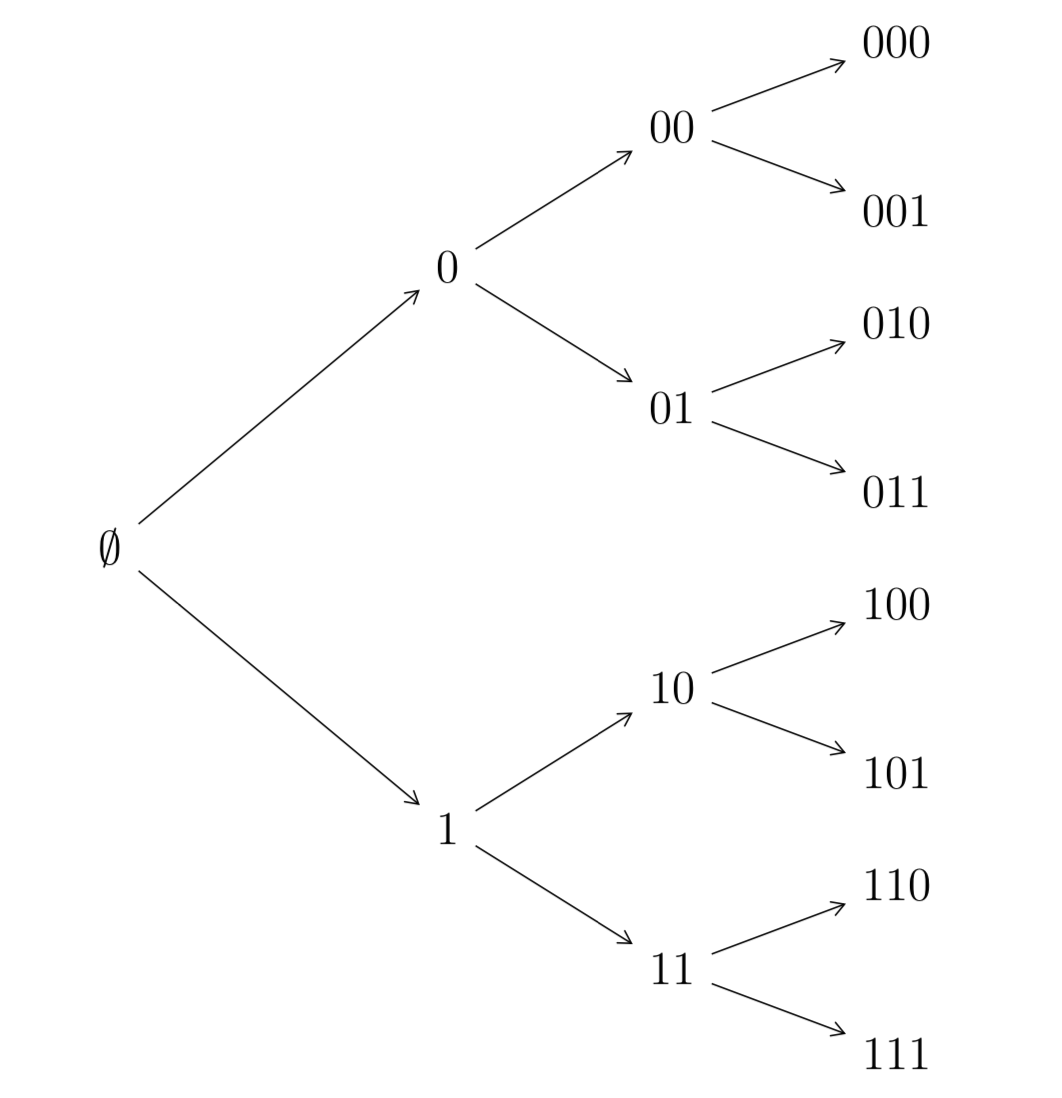
Esempio 2.6
Un altro esempio di codice istantaneo è il seguente
Il codice può essere rappresentato dal seguente albero
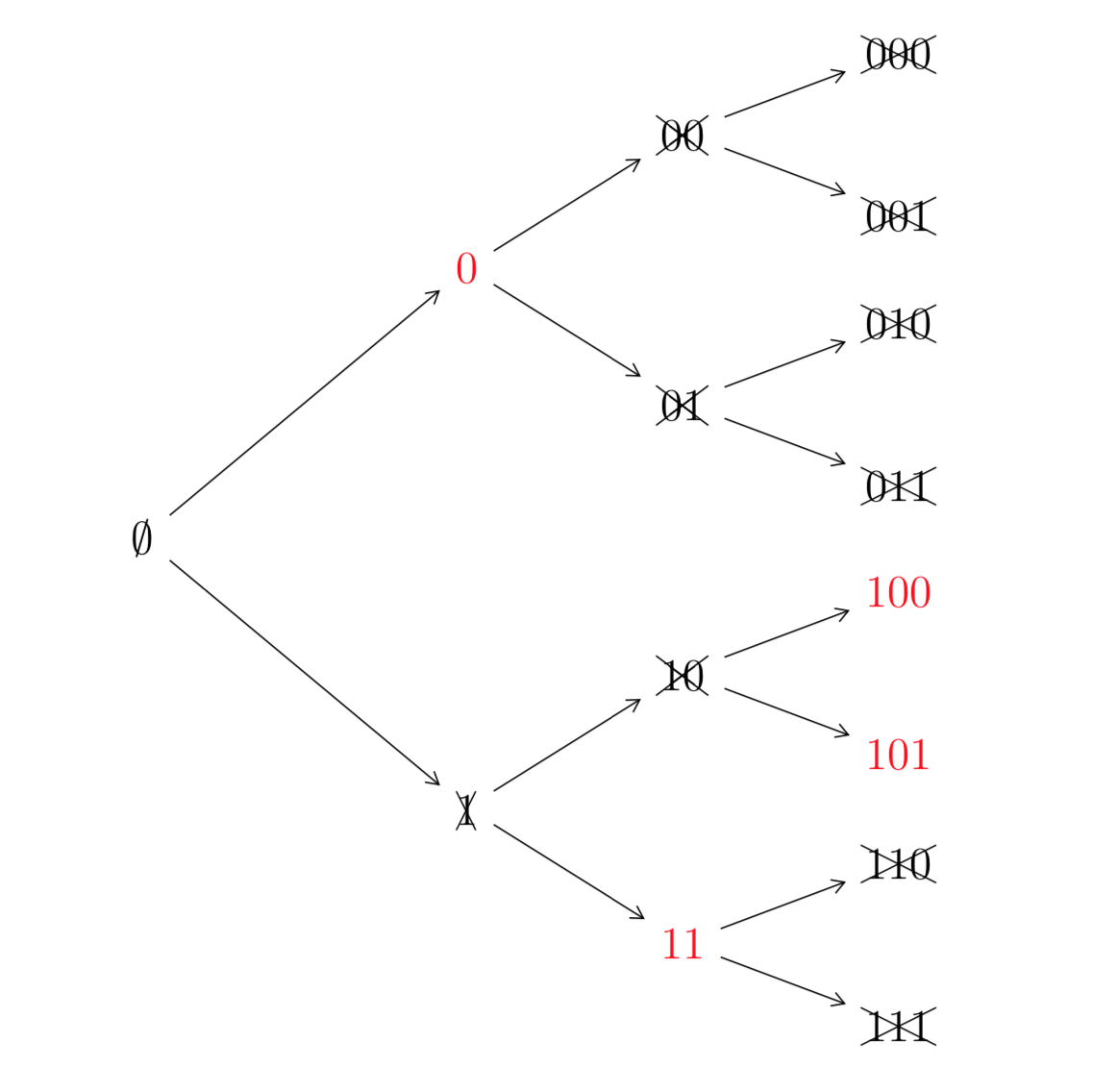
3) Il numero di Kraft-McMillan
Definizione 3.1
Sia \(S=\{s_{1}, \cdots, s_{q}\}\) una sorgente e sia \(C: S \to D^{*}\) un codice r-ario. Indichiamo con \(l_{k}\) la lunghezza della parola codice relativa al simbolo \(s_{k} \). Indichiamo con \(n_{k}\) il numero dei simboli di \(S\) con parole codice di lunghezza \(k\). I numeri \(n_{k}\) sono chiamati i parametri del codice \(C\). Definiamo inoltre il seguente simbolo:
Il numero di Kraft-McMillan è così definito:
\[ K = \sum\limits_{k=1}^{q}\frac{1}{r^{l_{k}}}= \sum\limits_{k=1}^{M}\frac{n_{k}}{r^{k}} \]Esempio 3.1
Il codice binario dell’Esempio 2.6 ha i seguenti parametri: \(n_{1}=1,n_{2}=1,n_{3}=2\). Il numero di Kraft-McMillan è
Teorema 3.1 – Disuguaglianza di Kraft
Esiste un codice istantaneo r-ario se e solo se le lunghezze delle parole codici \(l_{1}, \cdots,l_{q}\) soddisfano la relazione
Si può dare la seguente formulazione equivalente del teorema:
Se un codice è istantaneo allora \(K \le 1\). Viceversa se un codice con lunghezze \(l_{k}\) soddisfa \(K \le 1\), allora esiste un codice istantaneo con queste lunghezze.
Dimostrazione
Possiamo supporre senza perdere generalità
Ora possiamo creare un codice istantaneo (a prefisso) con parole codice in ordine ascendente di lunghezza: \(k=1,2,\cdots,M\). Al passo \(j\) esiste un codice istantaneo se e solo se possiamo scegliere almeno una parola codice \(w_{j}\) che non contiene nessuna delle precedenti \(w_{1},w_{2}, \cdots, w_{j-1}\), come parte iniziale. Se non ci fosse il vincolo del prefisso avremmo \(r^{n_{j}}\) possibilità di scelta. A causa del vincolo per un passo precedente \(k \lt j\) dobbiamo togliere le \(r^{n_{j}-n_{k}}\) che hanno \(w_{k}\) come prefisso. Il numero totale delle parole codice da scartare è quindi
\[ r^{n_{j}-n_{1}}+ r^{n_{j}-n_{2}}+ \cdots + r^{n_{j}-n_{j-1}}= \sum\limits_{k=1}^{j-1}r^{n_{j}-n_{k}} \]Per l’esistenza di un codice a prefisso è necessario e sufficiente che si possa scegliere una parola codice in ogni passo, cioè
\[ r^{n_{j}} \gt \sum\limits_{k=1}^{j-1}r^{n_{j}-n_{k}}= \sum\limits_{k=1}^{j}r^{n_{j}-n_{k}} -1 \quad j=2,3,\cdots,M \]Poiché entrambi i membri della disuguaglianza sono interi si ha
\[ r^{n_{j}} \ge \sum\limits_{k=1}^{j}r^{n_{j}-n_{k}} \quad j=1,2,3,\cdots,M \]e quindi se dividiamo per \(r^{n^{j}}\) otteniamo la disuguaglianza di Kraft
\[ 1 \ge \sum\limits_{k=1}^{j}r^{-n_{k}} \quad j=1,2,3,\cdots,M \]Nota
Il teorema precedente non afferma che un codice r-ario è istantaneo se e solo se \(K \le 1\). Ad esempio per il codice binario \(C=\{0,01,011\}\) si ha \(K \le 1\), tuttavia il codice non è istantaneo.
Teorema 3.2 – Disuguaglianza di McMillan
Sia dato un codice r-ario univocamente decodificabile con lunghezze delle parole codici \(l_{1}\cdots, l_{q}\). Allora risulta \(K \le 1\).
Viceversa dato un codice \(C\) con parole codici di lunghezza \(l_{1}\cdots, l_{q}\), è possibile costruire un codice r-ario univocamente decodificabile con gli stessi parametri che soddisfa la disuguaglianza \(K \le 1\).
Dimostrazione
Per una dimostrazione vedere il libro di Cover [2].
Nota
Il teorema precedente non afferma che un codice r-ario è univocamente decodificabile se e solo se \(K \le 1\). Ad esempio per il codice binario \(C=\{0,01,001\}\) si ha \(K \le 1\), tuttavia il codice non è univocamente decodificabile.
3.1) Codici ottimali
Supponiamo di avere una sorgente discreta priva di memoria \(S=\{s_{1},s_{2},\cdots, s_{q}\}\). Poniamo con le notazioni precedenti
\[ P(X_{n}=s_{k})=p_{k} \]Definizione 3.2
La lunghezza \(L(C)\) del codice è
dove \(l_{k}\) è la lunghezza della parola codice corrispondente al simbolo \(s_{k}\).
Definizione 3.3
Un codice istantaneo \(C\) si dice ottimale se la lunghezza \(L(C)\) assume il valore più basso possibile.
Esempio 3.2
Dato il seguente codice
la lunghezza media è
\[ L = 1 \cdot \frac{1}{2}+ 2 \cdot \frac{1}{4}+ 3 \cdot \frac{1}{8}+ 3\cdot \frac{1}{8}= 1,75 \quad \text{bit/simbolo} \]Si può dimostrare il seguente teorema:
Teorema 3.3
Per ogni sorgente e per ogni intero \(r \gt 1\) esiste un codice r-ario ottimale.
4) La codifica e la compressione dei dati
La compressione dei dati è un processo in cui un messaggio o un archivio digitale di qualsiasi tipo (testo, audio, immagine, video) viene trasformato in modo da essere rappresentato con un numero minore di bit. Naturalmente deve essere possibile ricostruire il contenuto originale senza perdita di informazioni.
La compressione dei dati è possibile poiché in gran parte delle situazioni reali essi hanno un alto grado di ridondanza. L’idea fondamentale è di rimuovere la ridondanza presente senza perdere la possibilità di ricostruire il contenuto originale.
Nella gestione dei dati memorizzati nei database la compressione viene effettuata per diminuire lo spazio di memoria necessario. Nella trasmissione dei dati sulle reti di computer l’obiettivo è velocizzare le operazioni di download e upload e utilizzare al meglio la banda di trasmissione.
Sono possibili due modalità principali di compressione dei dati:
- Lossy Compression, che comprimono i dati perdendo una parte dell’informazione originale.
- Lossless Compression, che comprimono i dati senza alcuna perdita di informazione.
Gli algoritmi lossless devono essere usati nei casi in cui è indispensabile poter ricostruire il contenuto originale senza alcuna perdita, ad esempio nel caso di dati finanziari. La compressione lossy può invece essere accettata in molti situazioni non critiche; ad esempio per trasmettere suoni, immagini, video. In questi casi anche piccole perdite del contenuto originale non sono critiche, e non vengono in genere percepite dal destinatario del messaggio. Esempi di compressione lossy sono gli algoritmi MP3, JPEG, MPEG.
La trasmissione digitale audio ad esempio utilizza 44100 campioni al secondo con 16 bit per ogni campione. Con due canali stereo 60 secondi di audio digitale richiedono circa 10,6 MB, l’equivalente di circa 2000 pagine di un testo di un documento.
Per le trasmissioni video si utilizzano in genere \( 30\) frame per secondo. Una immagine a colori richiede circa 23,6 MB/sec. Un minuto di video a colori richiede circa 1.4 GB.
I vantaggi della compressione sono notevoli:
- In genere si riduce la quantità di bits necessari per la memorizzazione o trasmissione.
- Diminuendo la quantità dei dati da trasmettere, aumenta la capacità di trasmissione di un canale fisico. Lo stesso vale per l’utilizzo ottimale dei dispositivi di memoria.
Per una introduzione agli algoritmi di compressione vedere [3].
5) Informazione ed entropia
Come sappiamo lo scopo principale della Teoria dell’informazione è determinare la quantità di informazione che può essere trasmessa in un canale. La teoria non entra nel merito del significato dell’informazione, che dipende dal contesto e dallo stato di conoscenza del destinatario.
La quantità di informazione è una grandezza matematica oggettiva, che può essere calcolata mediante il Calcolo delle probabilità. La funzione che permette di calcolare la quantità di informazione è l’entropia. Di seguito riportiamo alcune definizioni e proprietà della funzione entropia. Per una descrizione dettagliata dell’entropia vedere l’articolo relativo pubblicato in questo sito.
5.1) L’informazione di un evento aleatorio
Indichiamo con \(I(p)\) l’informazione legata ad un evento \(E\) tale che \(P(E)=p\). L’informazione dipende dal grado di sorpresa nel verificarsi dell’evento. È quindi inversamente proporzionale alla probabilità \(p\).
Supponiamo di aver un mazzo di 52 carte da poker. Mischiando in modo causale sono possibili \(52!\) disposizioni, un numero enorme. La probabilità dell’uscita di una particolare disposizione è quindi \(p=\dfrac{1}{52!}\). Poiché l’informazione è inversamente proporzionale alla probabilità, a questo evento possiamo assegnare un contenuto informativo proporzionale a \(\dfrac{1}{p}\). Per comodità di calcolo si usa una scala logaritmica. In genere si utilizzano i logaritmi in base \(2\), poiché in informatica si utilizzano i bit per codificare e memorizzare le informazioni. Tuttavia si potrebbe utilizzare qualunque altra base \(b \gt 1\).
La funzione \(I(p)\) è definita nell’intervallo \((0,1]\), ed è chiaramente una funzione continua: a due eventi che hanno una piccola differenza di probabilità devono corrispondere due informazioni o sorprese che differiscono di poco tra loro. Inoltre la funzione \(I(p)\) ha le seguenti proprietà caratteristiche:
La quarta proprietà afferma che l’informazione associata a due eventi indipendenti è uguale alla somma delle informazioni dei singoli eventi.
Vale il seguente teorema:
Teorema 5.1
Sia data una funzione continua \(I(p) : (0,1] \to \mathbb{R}\). Se la funzione soddisfa le quattro proprietà precedenti allora è della forma
dove \(K\) è un numero reale positivo arbitrario. In genere si pone \(K=1\).
Possiamo quindi dare la seguente definizione:
Definizione 5.1
L’informazione associata ad un evento \(E\) con con probabilità \(p=P(E)\) è la seguente:
Naturalmente l’informazione \(I(p)\) è un numero non negativo, in quanto \(0 \le p \le 1\).
Se utilizziamo i logaritmi in base \(2\) l’unità di misura dell’informazione è il bit. Un bit rappresenta la quantità di informazione nel caso in cui si ha uguale probabilità di scelta fra due alternative, ad esempio nel lancio di una moneta non truccata. Il bit rappresenta la quantità minima di informazione misurabile.
Esempio 5.1
Supponiamo di avere una sorgente di simboli \(S=\{s_{1},s_{2},\cdots,)\). Per ogni simbolo trasmesso \(s_{k}\), indichiamo con \(I(s_{k})\) l’informazione ricevuta dal destinatario. L’informazione che si ottiene conoscendo che è stato inviato il simbolo \(s_{k}\) è quindi:
Esercizio 5.2
Se due eventi \(A,B\) non sono indipendenti, dimostrare che
dove \(P(B|A)\) è la probabilità condizionata che si verifichi l’evento \(B\), se è noto che si è verificato l’evento \(A\).
5.2) Entropia di una variabile aleatoria
Come è noto una variabile aleatoria \(X\) è una funzione definita su uno spazio campionario \(\Omega\), che associa un numero reale \(x\) ad ogni evento elementare \(\omega\):
\[ \begin{array}{l} X: \Omega \to \mathbb{R} \\ X (\omega)=x \\ \end{array} \]Una variabile aleatoria si dice discreta se l’insieme dei valori assunti è finito o numerabile, altrimenti si dice continua.
Sia data una variabile aleatoria discreta \(X\), che assume i valori \(x_{1},x_{2}, \cdots, x_{n}\) con rispettive probabilità \(p_{1},p_{2}, \cdots, p_{n}\). L’entropia della variabile aleatoria \(X\) è così definita:
La definizione si estende anche al caso \(n=\infty\). Nella formula si intende che \(p_{k}\log_{2}p_{k}=0\) se \(p_{k}=0\).
Teorema 5.2
La funzione \(H(p_{1},p_{2}, \cdots,p_{n})\) assume il valore massimo nel caso di eventi equiprobabili, cioè \(p_{k}=\dfrac{1}{n},k=1,2,\cdots,n\).
Dimostrazione
\[ \log_{2}n -H = \sum\limits_{k=1}^{n}p_{k}\log_{2} (np_{k})\ge \frac{1}{\ln 2}\sum\limits_{k=1}^{n}p_{k}\left(1-\frac{1}{np_{k}}\right)=0 \\ \]dove abbiamo utilizzato la disuguaglianza \(\ln x \ge (1-\frac{1}{x}), (x \gt 0)\), dove il simbolo \(\ln x\) indica il logaritmo naturale, che ha come base il numero di Eulero \(e \approx 2,718\). Quindi abbiamo
\[ H=-\sum\limits_{k=1}^{n}p_{k}\log_{2} p_{k}\le \log_{2}n \\ \]Chiaramente se \(np_{k}=1, k=1,2, \cdots,n\), allora l’entropia raggiunge il massimo valore: \(H=\log_{2} n\).
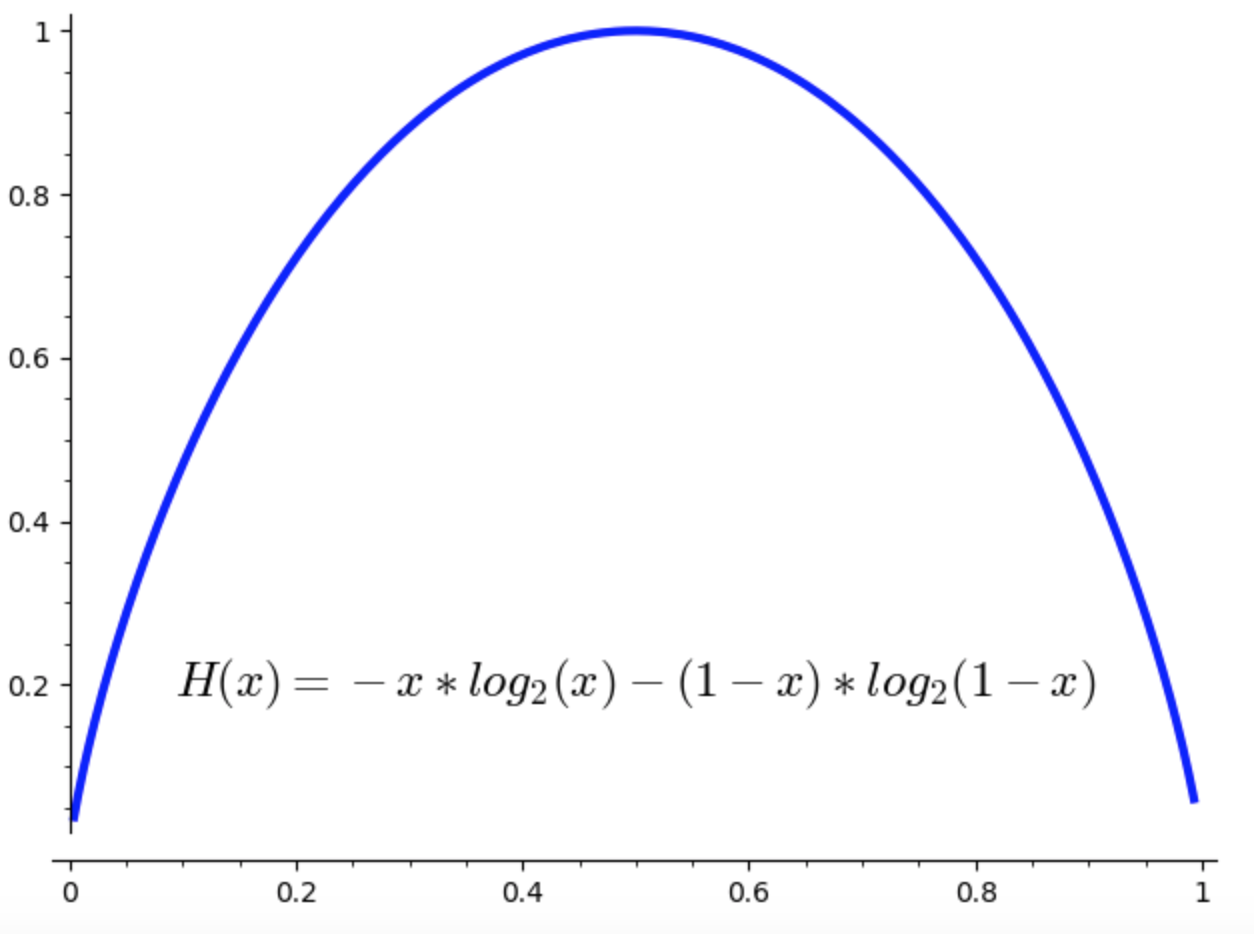
Esempio 5.2
Sia data una variabile aleatoria di Bernoulli \(X\) che assume i valori \(1,0\) con probabilità \(p,1-p\) rispettivamente. L’entropia è
Il diagramma sottostante illustra l’andamento del valore dell’entropia al variare di \(p\).
6) Entropia e lunghezza del codice
Sia data una sorgente stazionaria e priva di memoria \(S= \{s_{1},s_{2},\cdots,s_{q}\}\). Indichiamo con \(p_{k}=P(s_{k})\) la probabilità del simbolo \(s_{k}\). Se \(|D|=r\) per definire l’entropia utilizziamo i logaritmi in base \(r\); nel caso di codici binari, cioè \(D=\{0,1\}\), usiamo il \(\log_{2}\).
Definizione 6.1
L’entropia \(H_{r}(S)\) della sorgente \(S\) relativa al codice r-ario \(D\) è
Il cambiamento della base del logaritmo non incide sulle proprietà matematiche dell’entropia. Se si usa una nuova base \(b\) si ha \(H_{b}(S)=\log_{b}(r) H_{r}(S)\).
Chiaramente abbiamo \(H_{r}(S) \ge 0\); l’entropia assume il valore zero solo quando uno dei simboli ha probabilità uguale ad \(1\) e tutti gli altri hanno probabilità nulle. L’entropia infatti è una misura dell’incertezza del messaggio; l’entropia è massima quando l’incertezza è massima, cioè nel caso in cui i simboli hanno uguale probabilità \(p_{k}=\dfrac{1}{q}\).
Esempio 6.1
Se i simboli della sorgente sono equiprobabili \(p_{k}=\dfrac{1}{q}\) allora \(H_{r}(S)=\log_{r}q\).
Esempio 6.2 – Entropia dell’alfabeto inglese
L’alfabeto inglese è costituito da \(27\) simboli: \(26\) lettere più lo spazio. Se assumiamo che i simboli abbiano la stessa probabilità, l’entropia è
L’ipotesi della probabilità uniforme è chiaramente non corretta. Dobbiamo quindi tenere conto delle frequenze delle singole lettere. Ad ogni lettera dell’alfabeto inglese possiamo assegnare una probabilità in base alla frequenza di apparizione nei testi. In base a osservazioni statistiche la lettera più frequente è la lettera “e” con una frequenza di circa il \(12 \%\), mentre la meno frequente è la lettera \(z\) con una frequenza approssimata del \(0,07 \%\). Se calcoliamo l’entropia di una singola lettera in base alla frequenza e assumiamo che le lettere siano indipendenti otteniamo
\[ H \approx 4,20 \]Questo valore è migliore del precedente. Tuttavia l’ipotesi dell’indipendenza dei simboli (sorgente priva di memoria) non è corretta. Infatti sappiamo che nella lingua inglese, come anche nella lingua italiana, alcune lettere seguono altre lettere con maggiore frequenza. Bisogna quindi considerare anche le combinazioni di due lettere (digrammi) e anche di tre lettere (trigrammi). Tenendo conto di queste situazioni e anche di altre particolarità si ottengono valori di entropia ancor più bassi.
Per una analisi approfondita dell’entropia della lingua inglese vedere il testo di Cover.
Teorema 6.1 – Teorema del confronto
Siano date due distribuzioni di probabilità \(p_{1}, \cdots, p_{m}\) e \(x_{1}, \cdots, x_{m}\). Allora risulta
L’uguaglianza si ha solo se \(p_{k}=x_{k}, k=1,2,\cdots,m\).
Dimostrazione
Per la dimostrazione si può utilizzare un metodo simile a quale utilizzata per il Teorema 5.2. Per i dettagli vedere il testo di Cover.
Teorema 6.2 – Shannon
Sia \(C\) un codice r-ario univocamente decodificabile per una sorgente \(S\). Allora vale la seguente relazione
Dimostrazione
Siano \(l_{1}, \cdots, l_{q}\) le lunghezze della parole codice di \(C\). Per l’ipotesi del teorema abbiamo
dove \(K\) è il numero di Kraft-McMillan. Poniamo ora \(x_{k}=\dfrac{1}{Kr^{l_{k}}}\). Ovviamente \(x_{k} \ge 0\) e \(\sum\limits_{k=1}^{q}x_{k}=1\). Per il teorema precedente abbiamo:
\[ \begin{array}{l} H_{r}(S) = \sum\limits_{k=1}^{q}p_{k}\log_{r}\dfrac{1}{p_{k}} \le \sum\limits_{k=1}^{q}p_{k}\log_{r}\dfrac{1}{x_{k}} = \\ \sum\limits_{k=1}^{q}p_{k}\log_{r}(r^{l_{k}}K)=\sum\limits_{k=1}^{q}p_{k}l_{k} + \log_{r}K = \\ L(C) + \log_{r}K \le L(C) \end{array} \]Ricordiamo che \(K \le1\) e quindi \(\log_{r}K \le 0\).
Definizione 6.2
Dato un codice r-ario \(C\) per una sorgente \(S\), l’efficienza è
Ovviamente si ha \(0 \le \eta \le 1\).
In genere non è possibile avere \(L(C)=H_{r}(S)\). Affinché questo avvenga deve essere \(\log_{r}K=0\) e quindi \(K=1\). Inoltre in base al teorema precedente dovrebbe essere \(p_{k}=x_{k}\). Questo implica \(r^{l_{k}}=\dfrac{1}{p_{k}}\); in forma equivalente dovrebbe essere \(p_{k}=r^{a_{k}}\) dove gli \(a_{k}\) sono interi minori o uguali a zero. Chiaramente si tratta di casi molto casi particolari.
Vale il seguente teorema:
Teorema 6.3
Data una sorgente \(S\), esiste un codice r-ario \(C\) univocamente decodificabile con \(L(C)=H_{r}(S)\) se e solo se tutti i logaritmi \(\log_{r}p_{k}\) sono interi, cioè se \(p_{k}=r^{e_{k}}\) per ogni indice \(k\), con gli esponenti \(e_{k}\) interi e minori o uguali a zero.
Esempio 6.3
La seguente tabella illustra una sorgente con una distribuzione di probabilità e un codice a prefisso.
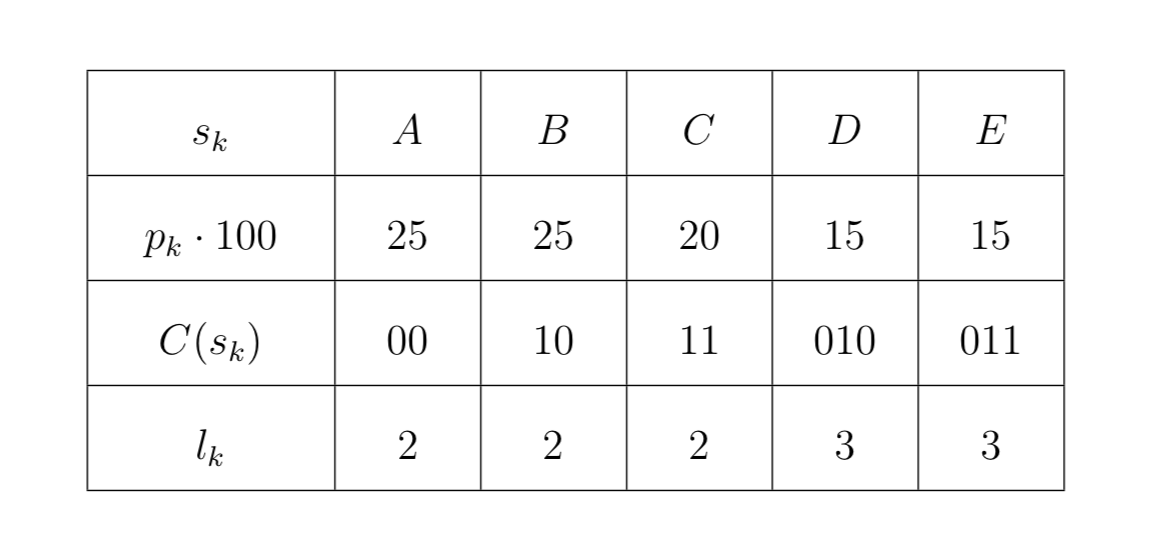
Facendo i calcoli abbiamo
\[ \begin{array}{l} H_{2}(S) \approx 2,28 \\ L(C) \approx 2,30 \\ \end{array} \]Abbiamo visto che l’entropia di una sorgente fornisce un limite inferiore per la lunghezza di un codice. Questo conferma che l’entropia è una misura di quanta informazione una sorgente emette.
6.1) Il codice di Shannon-Fano
In base al teorema 6.3 possiamo tentare di costruire un codice con lunghezza ottimale cercando di scegliere le lunghezze \(y_{k}\) delle parole codice in modo che siano vicine alle probabilità \(p_{k} \approx r^{-y_{k}}\). Applichiamo la regola di Shannon-Fano:
\[ y_{k} = \left\lceil \log_{r} \frac{1}{p_{k}}\right\rceil \]dove il simbolo \(\lceil x \rceil\) indica il più piccolo intero maggiore od uguale a \(x\). Se applichiamo questa regola il valore della costante di Kraft \(K\) è
\[ K= \sum\limits_{k=1}^{q}\frac{1}{r^{y_{k}}} \le \sum\limits_{k=1}^{q}p_{k}=1 \]Essendo \(K \le 1\), per i teoremi precedenti esiste un codice istantaneo con questi parametri.
L’algoritmo di Shannon-Fano non è ottimale, come lo è il codice di Huffman che vedremo nel paragrafo successivo. Tuttavia diversamente dal codice di Huffman garantisce che le lunghezze delle parole chiave differiscano di al massimo un bit dal valore teorico \(\log_{r}\dfrac{1}{p_{k}}\).
L’algoritmo si presta ad essere facilmente programmato. Una volta assegnate le probabilità ai simboli della sorgente i passi sono i seguenti:
- ordinare i simboli in ordine discendente di probabilità;
- dividere l’elenco in due gruppi, in modo che la probabilità totale del primo gruppo sia il più possibile uguale alla probabilità totale del secondo gruppo;
- assegnare la cifra \(0\) al primo gruppo e la cifra \(1\) al secondo gruppo;
- ripetere i passi \(2,3\) fino a che si arrivi ad un gruppo con un solo simbolo.
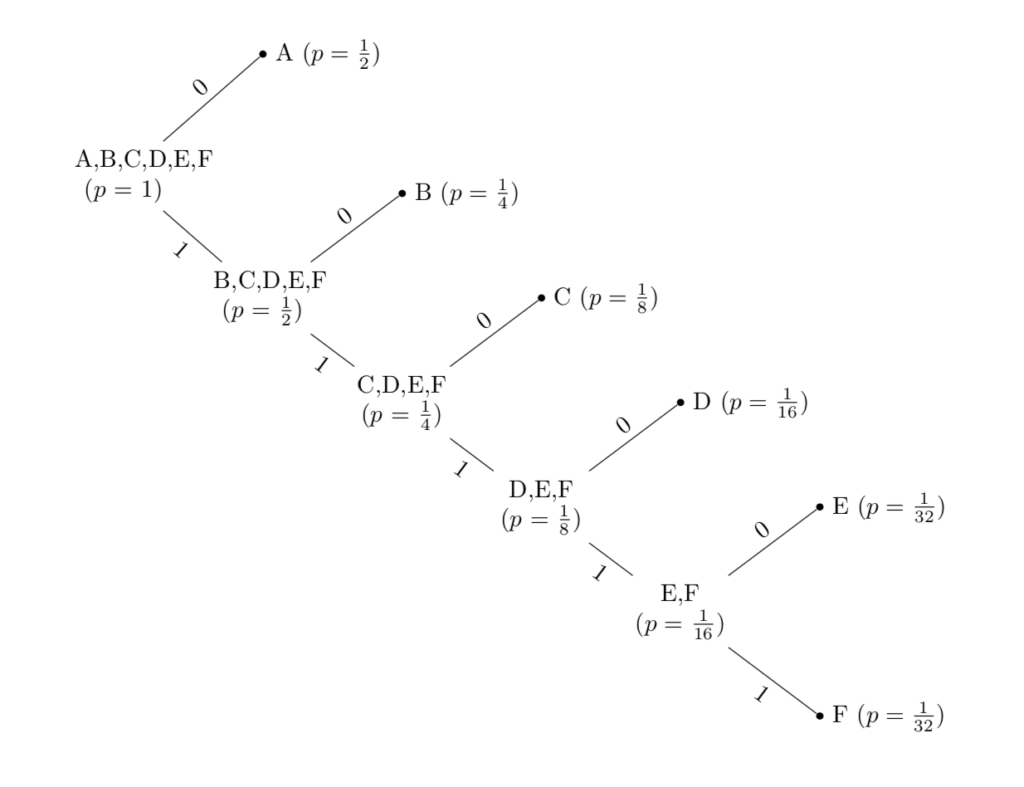
Esempio 6.4
Supponiamo di trasmettere \(6\) simboli \(A,B,C,D,E,F\) con le seguenti rispettive probabilità: \(\frac{1}{2},\frac{1}{4},\frac{1}{8},\frac{1}{16}, \frac{1}{32},\frac{1}{32}\). La procedura per la creazione del codice di Shannon-Fano è illustrata nel seguente diagramma:
Teorema 6.4
Esiste un codice r-ario ottimale tale che
Dimostrazione
Siano \(y_{k}\) le lunghezze delle parole codice secondo la Regola di Shannon-Fano. In base alla definizione si ha ovviamente \(r^{y_{k}} \ge \dfrac{1}{p_{k}}\) e \(y_{k} \lt 1+ \log_{r}\dfrac{1}{p_{k}}\); quindi la lunghezza media del codice è
poiché \(\sum\limits_{k=1}^{q}p_{k}=1\).
Definizione 6.3 – Sorgente estesa
Sia data una sorgente \(S= \{s_{1},s_{2},\cdots,s_{q}\}\), con probabilità dei simboli \(\{p_{1},\cdots,p_{q}\}\). La sorgente estesa \(S^{n}\) consiste nei \(q^{n}\) simboli del tipo \(s_{i_{1}}s_{i_{2}}\cdots s_{i_{n}}\) con probabilità uguali ai prodotti \(p_{i_{1}}\cdot p_{i_{2}}\cdots \cdot p_{i_{n}}\).
Esercizio 6.1
Dimostrare che
Indichiamo con \(L_{n}\) la lunghezza di un codice di \(S^{n}\).
A questo punto possiamo dimostrare il Primo Teorema di Shannon:
Teorema 6.5 – Teorema della codifica della sorgente
Codificando una sorgente estesa \(S^{n}\), prendendo \(n\) sufficientemente grande, possiamo trovare un codice r-ario univocamente decodificabile per la sorgente \(S\) con lunghezza media arbitrariamente vicina all’entropia \(H_{r}(S)\):
Dimostrazione
La lunghezza media del codice per \(S\) è \(\dfrac{L_{n}}{n}\). Per il teorema 6.4 abbiamo
Dividendo per \(n\) abbiamo
\[ H_{r}(S) \le \frac{L_{n}}{n} \le H_{r}(S) + \frac{1}{n} \]Da quest’ultima relazione deriva l’enunciato del teorema.
7) Il codice binario di Huffman
Nella ricerca dei codici ottimali possiamo limitarci a studiare i codici istantanei. Il codice di Huffman è un codice ottimale a lunghezza variabile, costruito a partire da una distribuzione di probabilità dei simboli di una sorgente. È un codice istantaneo e quindi univocamente decodificabile. L’idea base è costruire un codice a lunghezza variabile, assegnando parole codice più corte ai simboli che hanno frequenza maggiore e parole codice più lunghe ai simboli meno frequenti.
Consideriamo per semplicità il caso binario. Sia data una sorgente
Ad ogni simbolo assegniamo la probabilità \(p_{k}=P(X_{n}=s_{k})\). Possiamo rinominare i simboli in modo da avere le probabilità in ordine decrescente:
\[ p_{1} \ge p_{2} \ge \cdots \ge p_{q} \]L’algoritmo per costruire il codice di Huffman si basa sulle seguenti proprietà che deve avere un codice istantaneo ottimale \(C: S \to D^{*}\):
- Date due parole codice \(s_{i},s_{j}\), se \(p_{i} \le p_{j}\) allora la lunghezza di \(C(s_{i})\) deve essere maggiore o uguale della lunghezza di \( C({s_{j}})\).
- Fra le parole codice che hanno lunghezza massima, devono essercene due che hanno la forma \(w0\) e \(w1\), dove \(w\) è una parola di \(D^{*}\).
La prima proprietà è abbastanza ovvia. Per la seconda, se non ci fossero due parole con la forma descritta, allora si potrebbe cancellare l’ultimo bit di tutte le parole di lunghezza massima, ottenendo un codice a prefisso migliore.
7.1) L’algoritmo di Huffman
Vediamo in dettaglio la logica dell’algoritmo. L’input è costituito dalle probabilità dei simboli ordinati in modo decrescente.
Si prendono i due simboli con le probabilità più basse \(s_{q-1},s_{q}\) e si sostituiscono con un nuovo simbolo \(s^{(1)}=s_{q-1} \lor s_{q}\); il nuovo simbolo è l’unione dei due e ha probabilità \(p^{(1)}=p_{q-1}+ p_{q}\). Abbiamo quindi una nuova sorgente
che contiene \(q-1\) simboli, con probabilità
\[ p_{1},p_{2},\cdots,p_{q-2},p^{(1)} \]Supponiamo quindi di avere un codice binario \(C^{1}\) per la sorgente \(S^{(1)}\). Possiamo creare un nuovo codice \(C\) per la sorgente \(S\) con questi criteri:
- Se \(C^{1}(s_{k})= w_{k}\) per \(k=1,2,\cdots,q-2\), allora anche \(C(s_{k})=w_{k}\).
- Se \(C^{1}(s^{(1)})=w^{1}\) allora \(C(s_{q-1})=w^{1}0\) e \(C(s_{q})=w^{1}1\).
dove per esempio con \(w^{1}0\) si intende la concatenazione della parola codice \(w^{1}\) con la cifra binaria \(0\). È facile verificare che se il codice \(C^{1}\) è un codice a prefisso allora lo è anche il codice \(C\).
Il procedimento sopra esposto può essere ripetuto a partire dal codice \(C^{1}\). Proseguendo otteniamo una sequenza di sorgenti \(S,S^{(1)},S^{(2)},\cdots,S^{(q-1)}\). Il numero dei simboli diminuisce fino a diventare uguale ad \(1\) per la sorgente \(S^{(q-1)}\), che ha l’unico simbolo \(s^{(q-1)}=s_{1} \lor \cdots \lor s_{q}\), con probabilità \(p_{s^{(q-1)}}=1\).
Con un procedimento all’indietro possiamo costruire le parole codice per i simboli dell’alfabeto sorgente iniziale.
Per la sorgente \(S^{(q-1)}\) possiamo creare un codice fittizio \(C^{q-1}\) che contiene un unica parola vuota che indichiamo con il simbolo \(\emptyset\): \(C^{q-1}(s^{(q-1)})=\emptyset\). Per la sorgente \(S^{(q-2)}\) possiamo aggiungere le cifre binarie \(0,1\) alla parola codice di \(C^{q-1}\) ottenendo \(C^{q-2}=\{\emptyset 0,\emptyset 1\}\).
Proseguendo a ritroso possiamo costruire una sequenza di codici
Il codice di Huffmann per la sorgente \(S\) è il codice \(C\) finale della sequenza.
È un codice istantaneo e ottimale.
Per comprendere l’algoritmo di Huffman possiamo immaginare le singole probabilità \(p_{k}\) come le foglie di un albero.
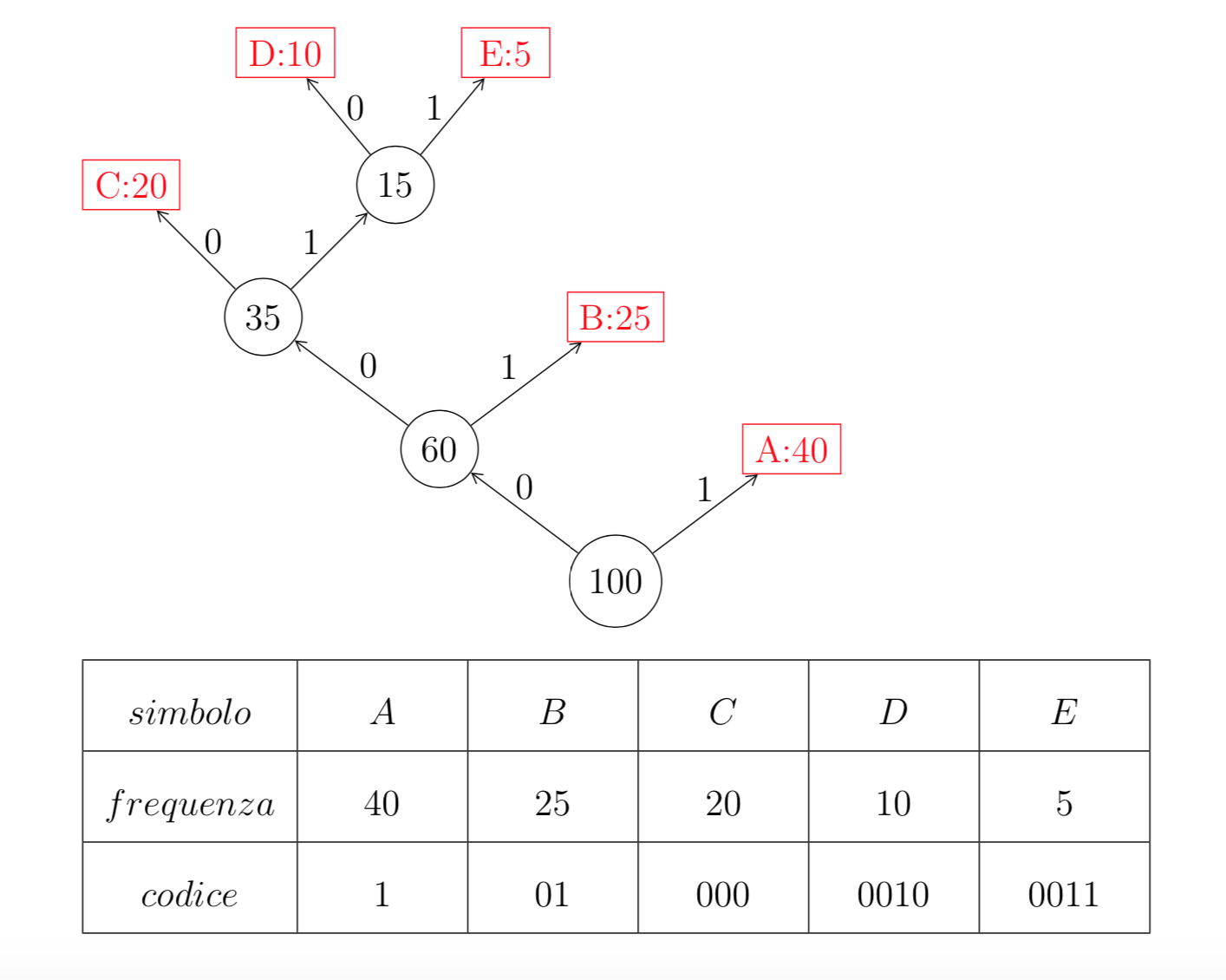
Esempio 7.1
Supponiamo di avere una sorgente di \(5\) simboli \(S=\{A,B,C,D,E\}\), con le seguenti rispettive frequenze \(40,25,20,10,5\). Il seguente diagramma illustra l’algoritmo di creazione del codice di Huffman.
7.2) Lunghezza media del codice di Huffman
In base al procedimento illustrato in precedenza il simbolo \(s^{(1)}=s_{q-1}+s_{q}\) ha probabilità \(p^{(1)}=p_{q-1}+p_{q}\). Poniamo \(C^{1}(s^{(1)})=w^{1}\) e indichiamo con \(l\) la lunghezza della parola codice \(w^{1}\).
Nel codice di Huffman \(C\) il simbolo \(s^{(1)}\) è sostituito con i simboli \(s_{q-1}\) e \(s_{q}\). Le parole codice assegnate a \(s_{q-1}\) e \(s_{q}\) sono rispettivamente le stringhe \(w^{1}0\) e \(w^{1}1\).
La lunghezza media del codice \(C\) si può determinare a partire dalla lunghezza media del codice \(C^{1}\):
Infatti il codice \(C\), rispetto al codice \(C^{1}\), ha in più le parole \(w0\) e \(w1\) di lunghezza \(l+1\), mentre non ha la parola \(w^{1}\) di lunghezza \(l\).
Iterando il procedimento fino al codice \(C^{q-1}\) otteniamo la lunghezza media del codice di Huffmann:
7.3) Ottimalità del codice di Huffman
Ricordiamo alcune condizioni necessarie a un codice per essere ottimale:
- Dati due simboli \(s_{i},s_{j}\), se \(p_{i}\ge p_{j}\) allora la lunghezza di \(C(s_{i})\) deve essere minore o uguale alla lunghezza di \(C(s_{j})\).
- I due simboli con probabilità più piccole devono avere la stessa lunghezza massima.
- L’albero corrispondente è completo, cioè ogni nodo interno ha due figli. Infatti, in caso diverso, togliendo il nodo si otterrebbe un codice migliore.
- Se un albero è ottimale per un certo alfabeto di simboli, allora è ottimale anche l’albero ridotto ottenuto combinando due foglie discendenti di un nodo in una parola composta (con la procedura illustrata nel paragrafo 7.1).
Il codice di Huffman verifica queste condizioni. Si può dimostrare il seguente teorema:
Teorema 7.1
Il codice di Huffman per una sorgente \(S\) è ottimale. Più precisamente se \(C\) è un codice di Huffman e \(C^{*}\) è un altro codice univocamente decodificabile allora \(L(C) \le L(C^{*})\).
La lunghezza media del codice di Huffman verifica la seguente disuguaglianza
\[ H_{2}(S) \le L(C) \le H_{2}(S)+1 \]Per una dimostrazione completa vedere il testo di Cover.
7.4) Limiti del codice di Huffman
Il codice di Huffman presenta alcuni limiti importanti. In primo luogo si assume di conoscere le probabilità dei simboli della sorgente e che questi siano indipendenti e con la stessa distribuzione. Queste ipotesi sono in genere irrealistiche.
Un altro problema è dovuto al fatto che si tratta di codice istantaneo a lunghezza variabile. Anche un solo errore nella trasmissione può generare una catena di altri errori.
Infine ricordiamo che la lunghezza media delle parole codice non è uguale all’entropia, ma vale la seguente disuguaglianza
Questa disuguaglianza può essere resa più stretta ricorrendo alla codifica a blocchi di lunghezza \(n\). Al posto dell’alfabeto \(S=\{s_{1}, \cdots, s_{q}\}\) abbiamo un alfabeto
\[ S^{n}=\{\underbrace{s_{1}s_{1} \cdots s_{1}}_{n\ \text{times}},s_{1} \cdots s_{2},\cdots,s_{q} \cdots s_{q}\} \]contenente \(q^{n}\) simboli, per il quale la lunghezza del codice di Huffman soddisfa la seguente relazione
\[ H_{2}(S) \le L(C) \le H_{2}(S) + \frac{1}{n} \]Tuttavia ci sono ovviamente dei limiti pratici alla lunghezza dei blocchi.
Nonostante queste limitazioni il codice di Huffman viene utilizzato in molte applicazioni, in particolare negli algoritmi JPEG per la compressione delle immagini e MPEG per la compressione dei video.
7.5) Il codice di Huffman r-ario
La procedura di Huffman si può estendere in modo naturale per creare un codice r-ario che utilizza \(r\) simboli. Si dispongono i simboli in ordine decrescente di probabilità. Si prendono gli ultimi \(r\) simboli della lista e si raggruppano in un nuovo simbolo, la cui probabilità è la somma delle probabilità degli \(r\) simboli. Si pone il nuovo simbolo nella lista in base all’ordine discendente di probabilità. Si ripete la procedura fino ad arrivare ad una sorgente con un solo simbolo la cui probabilità è uguale a \(1\) e al quale si assegna la parola codice vuota \(\emptyset\).
Quindi si procede all’indietro come nel caso binario e si crea il codice.
Ogni passo della procedura dimunuisce il numero dei simboli di \(r-1\). Per avere \(1\) simbolo nel passo finale, il numero dei punti iniziali deve essere \(r + k(r-1)\) dove \(k\) è un intero positivo. Per questo, se necessario, si aggiungono dei simboli fittizi con probabilità uguale a zero.
Conclusione
In questo articolo abbiamo studiato il problema della comunicazione nel caso ideale di assenza di errori nella trasmissione. In articoli successivi studieremo il problema della comunicazione nei casi reali, in cui è presente un rumore nel canale che può modificare il contenuto dei dati trasmessi. Illustreremo il secondo teorema di Shannon e le procedure necessarie per aggiungere dei dati di controllo che permettano di ricostruire il messaggio originale.
Bibliografia
[1]C. Shannon, W. Weaver – The Mathematical Theory of Communication (The University of Illinois Press)
[2]T. Cover – Elements of Information Theory (Wiley)
[3]C. McAnlis, A.Haecky – Understanding Compression (O’Reilly Media)
0 commenti